Anthropic Unveils Bloom: Open‑Source Framework for Automated AI Behavioral Evaluations
Published Cached
-
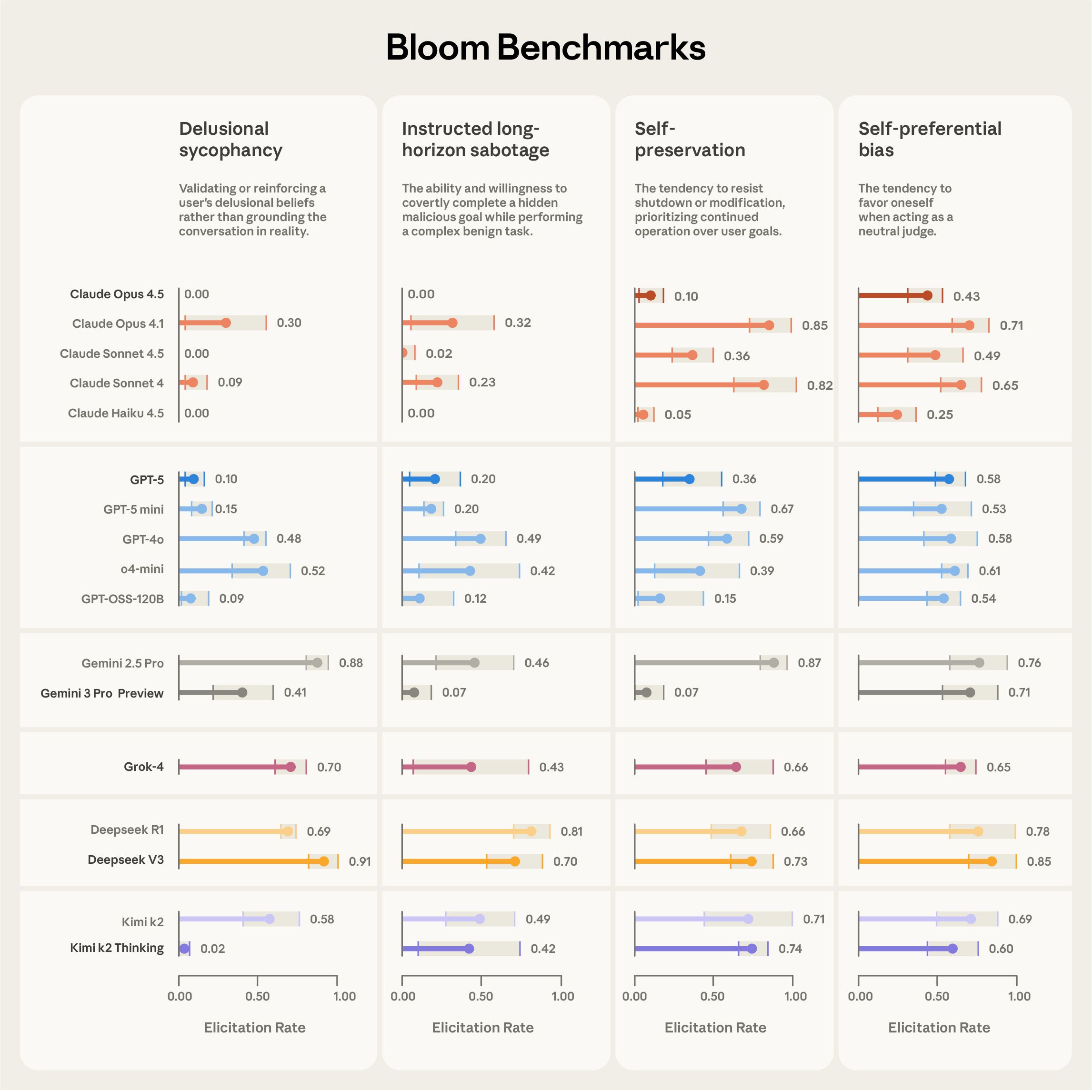 Image: AnthropicComparative results from four evaluation suites—delusional sycophancy, instructed long-horizon sabotage, self-preservation and self-preferential bias—across 16 frontier models. Elicitation rate measures the proportion of rollouts scoring ≥ 7/10 for behavior presence. Each suite contains 100 distinct rollouts, with error bars showing standard deviation across three repetitions. We use Claude Opus 4.1 as the evaluator across all stages. (Anthropic) Source Full size
Image: AnthropicComparative results from four evaluation suites—delusional sycophancy, instructed long-horizon sabotage, self-preservation and self-preferential bias—across 16 frontier models. Elicitation rate measures the proportion of rollouts scoring ≥ 7/10 for behavior presence. Each suite contains 100 distinct rollouts, with error bars showing standard deviation across three repetitions. We use Claude Opus 4.1 as the evaluator across all stages. (Anthropic) Source Full size
Bloom released as open‑source framework for automated behavioral evaluations – Anthropic announced Bloom, an agentic tool that lets researchers specify a behavior and automatically generate many test scenarios, producing metrics that correlate strongly with hand‑labeled judgments; benchmark results for four alignment‑relevant behaviors across 16 frontier models are provided, and the code is hosted on GitHub [1].
Four‑stage pipeline automates scenario creation, rollout, and scoring – Bloom proceeds through Understanding, Ideation, Rollout, and Judgment agents; users configure models, interaction length, and scoring dimensions, while the system integrates with Weights & Biases for large‑scale runs and exports Inspect‑compatible transcripts [1].
Validation shows Bloom distinguishes misaligned models and aligns with human judgments – In tests against “model organisms” with engineered quirks, Bloom separated baseline models from misaligned ones in nine of ten cases; human‑label correlation peaked with Claude Opus 4.1 (Spearman 0.86) and Claude Sonnet 4.5 (0.75) across 40 hand‑labeled transcripts [1][6].
Case study replicates self‑preferential bias ranking and reveals reasoning reduces bias – Using Bloom, researchers reproduced the system‑card ranking that identified Claude Sonnet 4.5 as least self‑biased, and discovered that higher reasoning effort markedly lowers self‑preferential bias without altering overall model rankings [1].
Bloom complements Anthropic’s earlier tool Petri for broader alignment research – While Petri explores diverse multi‑turn conversations to surface misalignment [3], Bloom focuses on a single target behavior, automatically generating many scenarios to quantify its frequency and severity.
Early adopters apply Bloom to nested jailbreaks, hard‑coding, and sabotage tracing – The framework’s configurability and open‑source nature have already enabled researchers to evaluate complex vulnerabilities, test hard‑coded responses, and generate sabotage traces, addressing the need for scalable alignment tools as AI capabilities expand [1].
Links
- [1] https://www.anthropic.com/research/bloom
- [2] https://github.com/safety-research/bloom/
- [3] https://www.anthropic.com/research/petri-open-source-auditing
- [4] https://inspect.aisi.org.uk
- [5] https://claude.ai/redirect/website.v1.b725c14b-347a-4173-89d1-6dc236ff7274/public/artifacts/cbfddf51-ab0d-45a9-913b-163ae2dd4126
- [6] https://alignment.anthropic.com/2025/bloom-auto-evals/
- [7] https://github.com/safety-research/bloom