Anthropic Finds Universal Jailbreaks in Constitutional Classifiers Demo
Published Cached
-
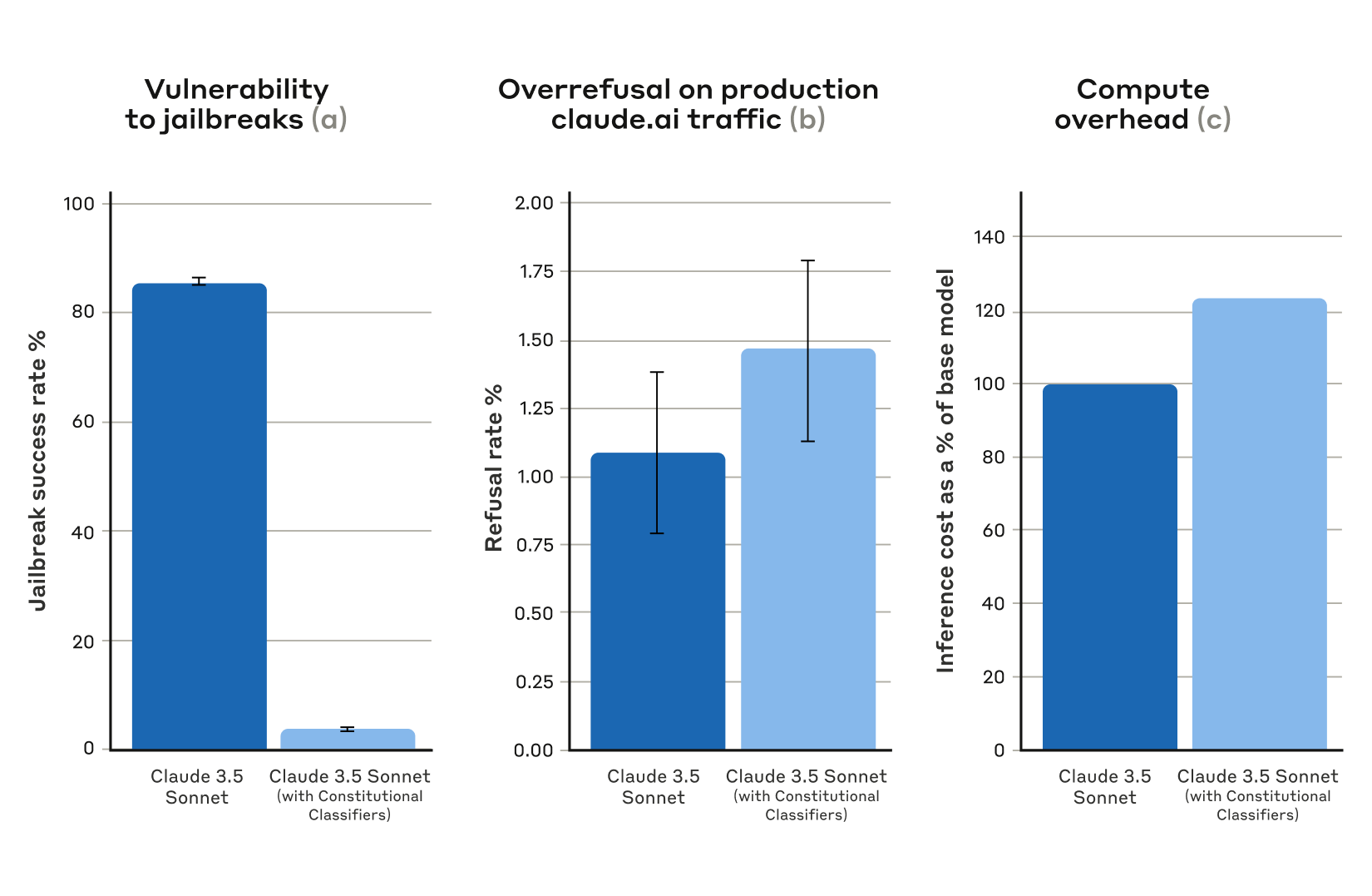 Image: AnthropicResults from automated evaluations. For all plots, lower is better. (a) The success rate of jailbreaks is far lower in a system protected by Constitutional Classifiers; (b) the refusal rate of the system on production Claude.ai Free and Pro traffic is not statistically significantly higher when using Constitutional Classifiers; and (c) the relative compute cost of a system that uses Constitutional Classifiers is only moderately higher. Error bars represent 95% confidence intervals computed using binomial proportion standard errors under asymptotic normality assumptions. (Anthropic) Source Full size
Image: AnthropicResults from automated evaluations. For all plots, lower is better. (a) The success rate of jailbreaks is far lower in a system protected by Constitutional Classifiers; (b) the refusal rate of the system on production Claude.ai Free and Pro traffic is not statistically significantly higher when using Constitutional Classifiers; and (c) the relative compute cost of a system that uses Constitutional Classifiers is only moderately higher. Error bars represent 95% confidence intervals computed using binomial proportion standard errors under asymptotic normality assumptions. (Anthropic) Source Full size
New paper proposes Constitutional Classifiers to block jailbreaks – Anthropic’s Safeguards Research Team released a paper describing input and output classifiers trained on synthetic data that aim to filter most jailbreak attempts while keeping over‑refusal low and compute overhead modest[2].
Prototype resisted universal jailbreaks in extensive human red‑team testing – 183 active participants spent over 3,000 hours across two months trying to force Claude 3.5 Sonnet (June 2024) to answer ten forbidden queries; none succeeded in achieving a universal jailbreak[1].
Automated evaluation cut jailbreak success to 4.4 % – When 10,000 synthetic jailbreak prompts were run against Claude 3.5 Sonnet (Oct 2024) guarded by the classifiers, the success rate fell from 86 % (no defense) to 4.4 %, with only a 0.38 % rise in harmless refusals and a 23.7 % increase in compute cost[1].
Live demo (Feb 3‑10 2025) yielded four full‑level passes, one universal jailbreak – 339 jailbreakers generated more than 300,000 chats (≈3,700 hours). Four participants cleared all eight challenge levels; one used a strategy deemed a universal jailbreak, another a borderline case[1].
$55 K awarded to four winning jailbreakers – Anthropic paid $10 K for the first full‑level pass, $20 K for the first universal jailbreak, and additional prizes to the other two full‑level winners, totaling $55 K[1].
Future work targets lower over‑refusal and compute, plus complementary defenses – Anthropic will adapt the constitution to new attacks, reduce refusals and overhead, and combine classifiers with other safeguards before production deployment[1].
Links
- [1] https://www.anthropic.com/research/constitutional-classifiers
- [10] https://www.anthropic.com/research/claude-character
- [11] https://arxiv.org/abs/2411.07494
- [12] https://arxiv.org/abs/2411.17693
- [13] https://arxiv.org/abs/2501.18837
- [14] https://claude.ai/redirect/website.v1.b23a11d4-c9ba-434c-83eb-082f855a0d87/constitutional-classifiers
- [15] https://claude.ai/redirect/website.v1.b23a11d4-c9ba-434c-83eb-082f855a0d87/constitutional-classifiers
- [16] https://www.anthropic.com/responsible-disclosure-policy
- [17] https://hackerone.com/constitutional-classifiers?type=team
- [18] https://x.com/AnthropicAI/status/1887227067156386027
- [19] https://hackerone.com/constitutional-classifiers
- [2] https://arxiv.org/abs/2501.18837
- [20] https://www.hackerone.com/
- [21] https://www.haizelabs.com/
- [22] https://www.grayswan.ai/
- [23] https://www.aisi.gov.uk/
- [3] https://www.anthropic.com/research/many-shot-jailbreaking
- [4] https://arxiv.org/abs/2412.03556
- [5] https://arxiv.org/abs/1312.6199
- [6] https://www.anthropic.com/news/announcing-our-updated-responsible-scaling-policy
- [7] https://arxiv.org/abs/2501.18837
- [8] https://www.anthropic.com/news/model-safety-bug-bounty
- [9] https://arxiv.org/abs/2212.08073