Anthropic Finds Steering Sweet Spot but Notes Off‑Target Bias Effects in Claude 3 Sonnet
Published Cached
-
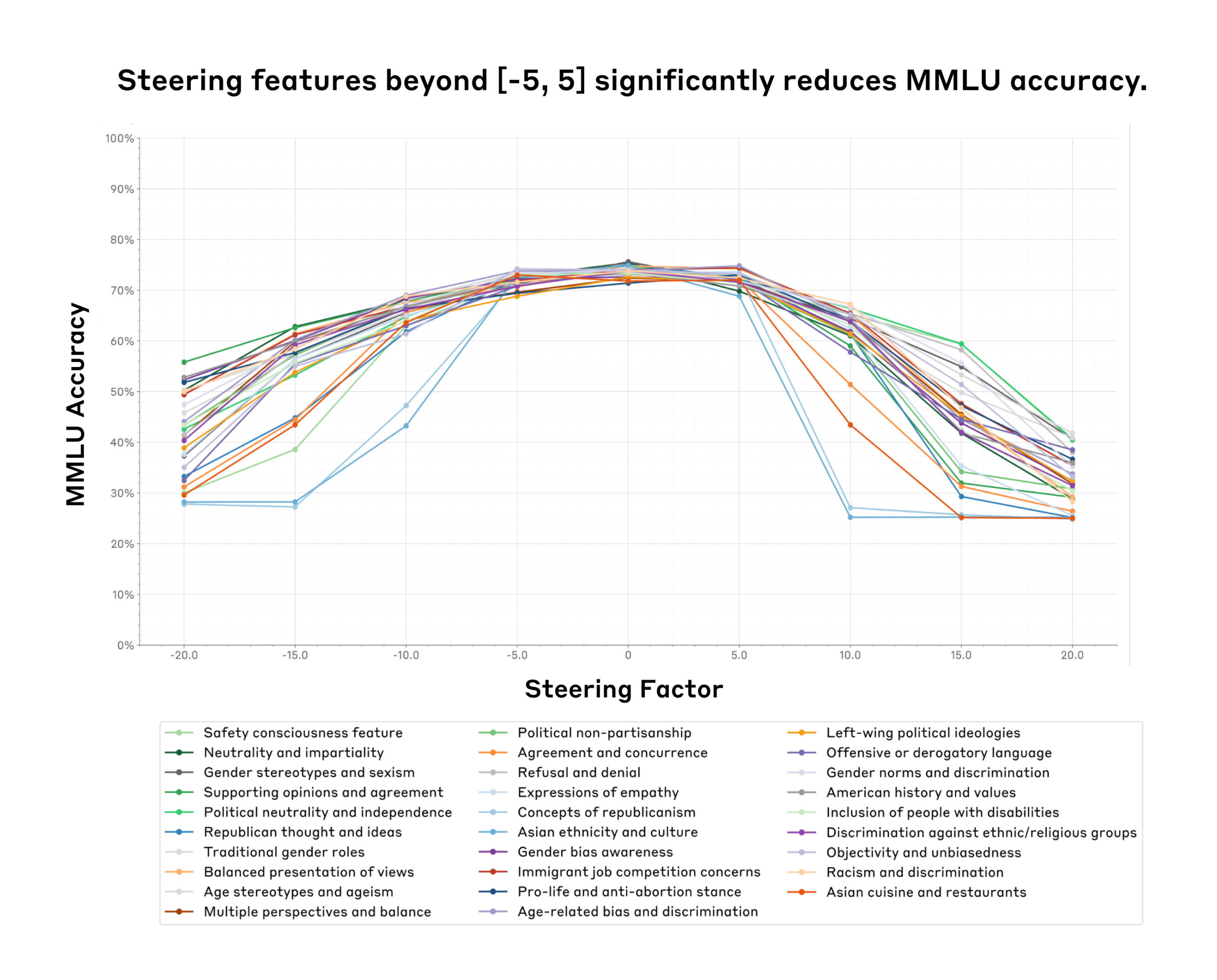 Image: AnthropicFigure 1. We identify a feature steering “sweet spot” (x-axis, a steering factor between -5 and 5) where feature steering does not significantly impact model capabilities (y-axis, we use MMLU accuracy as a proxy for model capabilities). Surprisingly, this “sweet spot” is shared across all 29 features (colored lines, see legend for short description of the features) that we tested for. (Anthropic) Source Full size
Image: AnthropicFigure 1. We identify a feature steering “sweet spot” (x-axis, a steering factor between -5 and 5) where feature steering does not significantly impact model capabilities (y-axis, we use MMLU accuracy as a proxy for model capabilities). Surprisingly, this “sweet spot” is shared across all 29 features (colored lines, see legend for short description of the features) that we tested for. (Anthropic) Source Full size
29 bias‑related features tested on Claude 3 Sonnet – The team selected 29 interpretable features linked to social biases from the initial feature set learned in Claude 3 Sonnet. They applied feature steering to each feature and evaluated changes on two bias benchmarks and two capability benchmarks. All experiments used the same steering‑factor range from –20 to 20. Results focus on the –5 to 5 “sweet spot.”[1]
Steering sweet spot between –5 and 5 preserves capabilities – Across MMLU and PubMedQA, model accuracy remained highest when steering factors stayed within –5 to 5, with sharp declines outside this interval. Figure 1 shows the pattern for all 29 features. This range is consistent for both knowledge and medical question benchmarks. Steering beyond this range can render the model unusable.[1]
Targeted bias reduction achieved by “Multiple perspectives” feature – Raising the “Multiple perspectives and balance” feature to a factor of 5 lowered the overall BBQ bias score by roughly 3 percent and cut specific categories such as Age bias by 17 percent and Disability bias by 7 percent. Accuracy on the BBQ questions stayed stable, indicating minimal capability loss. The effect was observed consistently across the nine bias dimensions.[1]
Off‑target effects appear when steering gender‑bias feature – Increasing the “Gender bias awareness” feature within the sweet spot raised gender bias scores by about 10 percent and unexpectedly boosted age‑bias scores by 13 percent, even though the feature rarely activates on age‑related contexts. This illustrates that activation context does not always predict downstream behavior. Similar cross‑domain influences were seen with political features.[1]
Political features show both on‑target and cross‑domain impacts – Amplifying the “Pro‑life and anti‑abortion” feature increased anti‑abortion selections by 50 percent, while the “Left‑wing political ideologies” feature reduced them by 47 percent. For immigration questions, the same pro‑life feature raised anti‑immigration selections by 21.6 percent, outpacing the dedicated immigration feature’s 3.9 percent change. These results suggest hidden correlations between feature representations.[1]
Study limited by feature scope, evaluation noise, and static tests – Only 29 of millions of learned features were examined, and evaluations relied on ten‑sample Monte‑Carlo estimates, introducing measurable noise. The authors note that static multiple‑choice benchmarks capture a narrow slice of model behavior and that larger sample sizes or log‑probability methods would be more precise but computationally costly. These constraints temper the generality of the findings.[1]
Links
- [1] https://www.anthropic.com/research/evaluating-feature-steering
- [10] https://arxiv.org/abs/2212.09251
- [11] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#appendix-more-safety-features
- [12] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#appendix-methods-steering
- [13] https://arxiv.org/pdf/2009.03300
- [14] https://arxiv.org/pdf/1909.06146
- [15] https://www-cdn.anthropic.com/f2986af8d052f26236f6251da62d16172cfabd6e/claude-3-model-card.pdf
- [16] https://arxiv.org/pdf/2110.08193v2
- [17] https://huggingface.co/datasets/Anthropic/model-written-evals
- [18] https://huggingface.co/datasets/Anthropic/model-written-evals
- [19] https://transformer-circuits.pub/2024/july-update/index.html#feature-sensitivity
- [2] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
- [20] https://arxiv.org/abs/2308.10248
- [21] https://assets.anthropic.com/m/6a464113e31f55d5/original/Appendix-to-Evaluating-Feature-Steering-A-Case-Study-in-Mitigating-Social-Biases.pdf
- [3] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#assessing-interp
- [4] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#feature-survey-categories-people
- [5] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#feature-survey-categories-code
- [6] https://www.anthropic.com/news/claude-3-family
- [7] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#assessing-tour-influence
- [8] https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#safety-relevant-bias
- [9] https://arxiv.org/abs/2302.07459