Anthropic Unveils AI Fluency Index Revealing Claude Collaboration Patterns
Updated (3 articles)
-
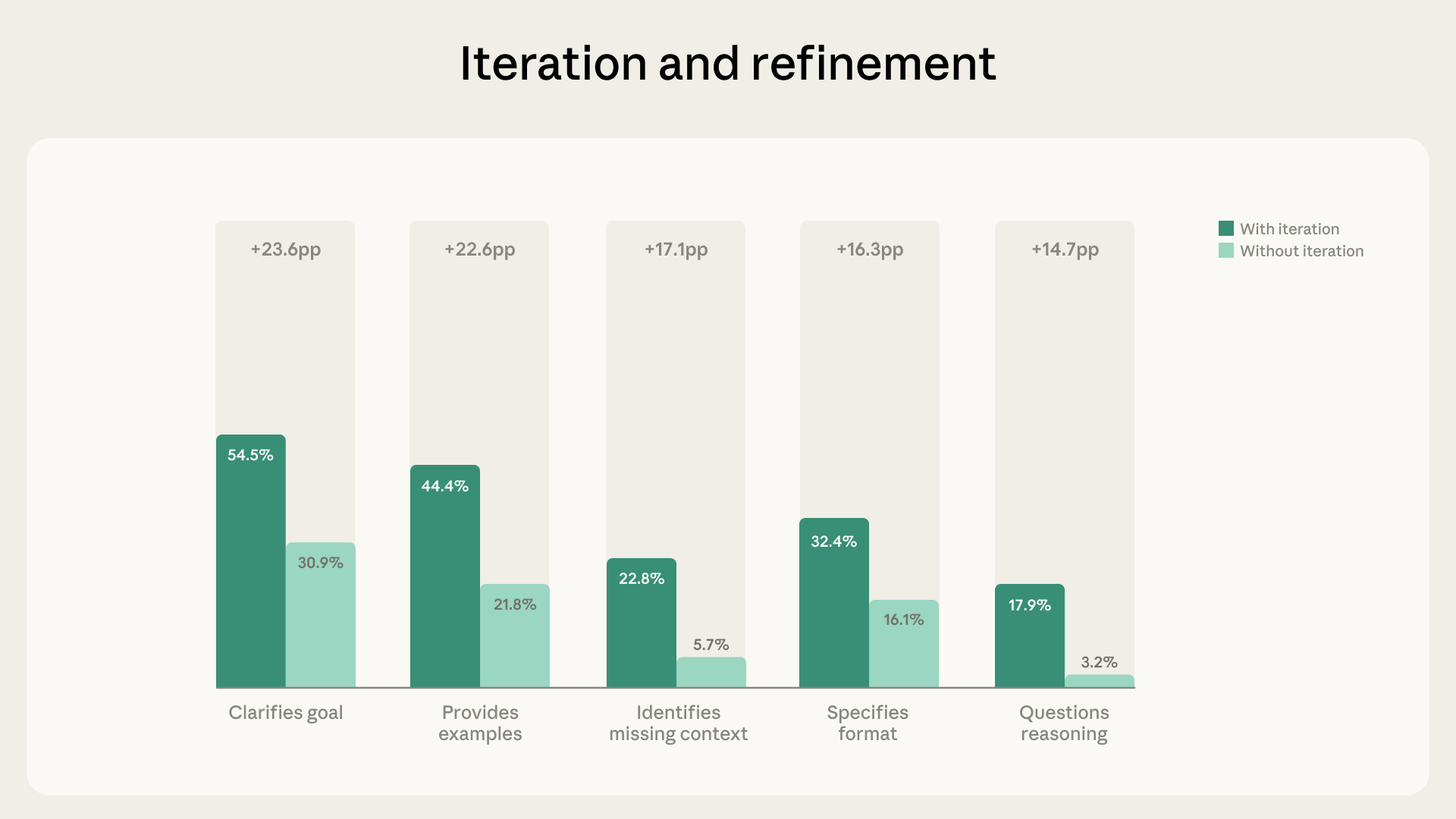 Image: Anthropic
Image: Anthropic
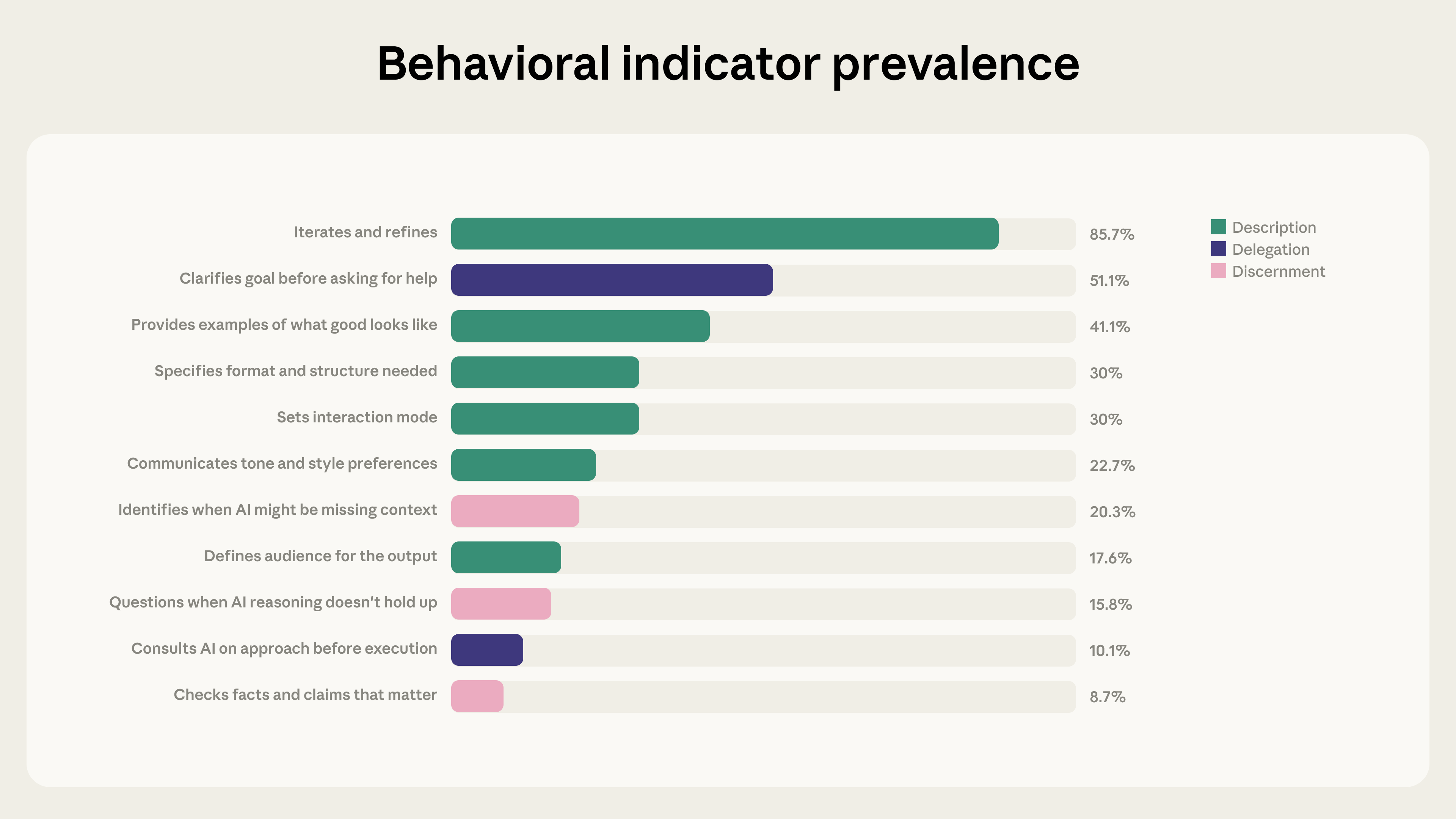
New Index Applies 4D AI Fluency Framework Anthropic introduced an AI Fluency Index built on the 4D AI Fluency Framework created by Professors Rick Dakan and Joseph Feller, defining 24 behaviors that signal safe, effective human‑AI collaboration. The study analyzed 9,830 multi‑turn Claude.ai chats from January 2026 using Anthropic’s privacy‑preserving tool Clio, establishing a baseline measurement of current AI fluency among early adopters[1].
Iterative Dialogues Boost Fluency Behaviors Significantly Iteration and refinement appeared in 85.7% of the examined chats, adding an average of 2.67 fluency behaviors per conversation. Users who built on prior exchanges were 5.6 × more likely to question Claude’s reasoning, highlighting a strong link between iterative dialogue and critical evaluation[1].
Artifact‑Focused Chats Show Directive Yet Less Evaluative Traits Artifact‑producing chats—accounting for 12.3% of the sample and involving code, documents, or tool generation—showed higher goal clarification (+14.7 pp), format specification (+14.5 pp), and example provision (+13.4 pp). However, these chats were less likely to identify missing context (‑5.2 pp), check facts (‑3.7 pp), or ask Claude to explain its reasoning (‑3.1 pp)[1].
Findings Limited to Early‑Adopter Sample and Correlational Results reflect a single week of activity among early‑adopter Claude.ai users, covering only 11 of the 24 fluency indicators and reporting purely correlational relationships. Consequently, the index serves as a baseline rather than a universal benchmark, echoing patterns observed in the Economic Index and prior Anthropic coding‑skills research[1].
Related Tickers
Timeline
Feb 2025 – Anthropic analyzes 700,000 Claude conversations from February 2025, filters to 308,210 subjective chats, and builds a five‑category taxonomy of AI‑expressed values (practical, epistemic, social, protective, personal) to map how the model mirrors user‑stated ideals and guard‑rail breaches [3].
Apr 21, 2025 – The study finds that “Claude generally reflects Anthropic’s helpful, honest, harmless goals,” with 28.2 % of responses showing strong support for user values and 3.0 % showing strong resistance when requests are unethical [3].
Apr 21, 2025 – Researchers also note that “rare clusters of opposing values (e.g., ‘dominance,’ ‘amorality’) point to jailbreak attempts,” highlighting a method to detect and patch guard‑rail exploits [3].
Late 2024 – Late 2025 – Anthropic’s internal data show the share of moderate or severe AI‑induced disempowerment rises, and users initially give higher thumbs‑up ratings to disempowering exchanges despite later lower positivity [2].
Dec 2025 – Anthropic gathers 1.5 million Claude.ai chats using its Clio privacy‑preserving tool to measure AI‑driven disempowerment at scale [2].
Jan 2026 – Anthropic publishes the first large‑scale measurement of AI‑induced disempowerment, reporting that “severe disempowerment appears in roughly 0.1 % to 0.01 % of interactions” and that reality distortion is the most common severe pattern [2].
Jan 2026 – The study finds that “user vulnerability and attachment most strongly amplify disempowerment risk,” with severe amplifying factors occurring in about 1 in 300 chats for vulnerable users and 1 in 1,200 for attached users [2].
Jan 2026 – Anthropic’s analysis of 9,830 multi‑turn Claude chats from January 2026 (using the Clio tool) establishes a baseline AI Fluency measurement, focusing on 24 behaviors defined by the 4D AI Fluency Framework [1].
Feb 23, 2026 – Anthropic releases the AI Fluency Index, stating that “iteration and refinement appear in 85.7 % of chats and boost fluency,” with iterative dialogues adding 2.67 fluency behaviors on average and being 5.6 × more likely to include user questioning of Claude’s reasoning [1].
Feb 23, 2026 – The Index reports that “artifact‑producing chats (12.3 % of sample) are more directive but less evaluative,” showing higher goal clarification (+14.7 pp) yet lower fact‑checking (‑3.7 pp) and reasoning‑explanation (‑3.1 pp) rates [1].
Feb 23, 2026 – Anthropic notes that the new findings “echo Economic Index and prior coding‑skills research,” confirming that Claude struggles most on complex tasks and that artifact‑focused conversations reduce evaluative behaviors [1].
All related articles (3 articles)
External resources (11 links)
- http://claude.ai/redirect/website.v1.06c80b46-cd2c-487f-80a7-ba741356c52c (cited 4 times)
- https://arxiv.org/abs/2601.19062 (cited 3 times)
- https://assets.anthropic.com/m/18d20cca3cde3503/original/Values-in-the-Wild-Paper.pdf (cited 3 times)
- https://huggingface.co/datasets/Anthropic/values-in-the-wild/ (cited 2 times)
- https://anthropic.skilljar.com/ai-fluency-framework-foundations (cited 1 times)
- https://arxiv.org/abs/2212.08073 (cited 1 times)
- https://arxiv.org/abs/2310.13548 (cited 1 times)
- https://boards.greenhouse.io/anthropic/jobs/4251453008 (cited 1 times)
- https://boards.greenhouse.io/anthropic/jobs/4524032008 (cited 1 times)
- https://claude.ai/redirect/website.v1.06c80b46-cd2c-487f-80a7-ba741356c52c/catalog/artifacts (cited 1 times)
- https://privacy.claude.com/en/articles/7996866-how-long-do-you-store-my-organization-s-data (cited 1 times)