Anthropic Publishes AI Fluency Index Showing Iterative Dialogue Boosts User Evaluation
Updated (4 articles)
-
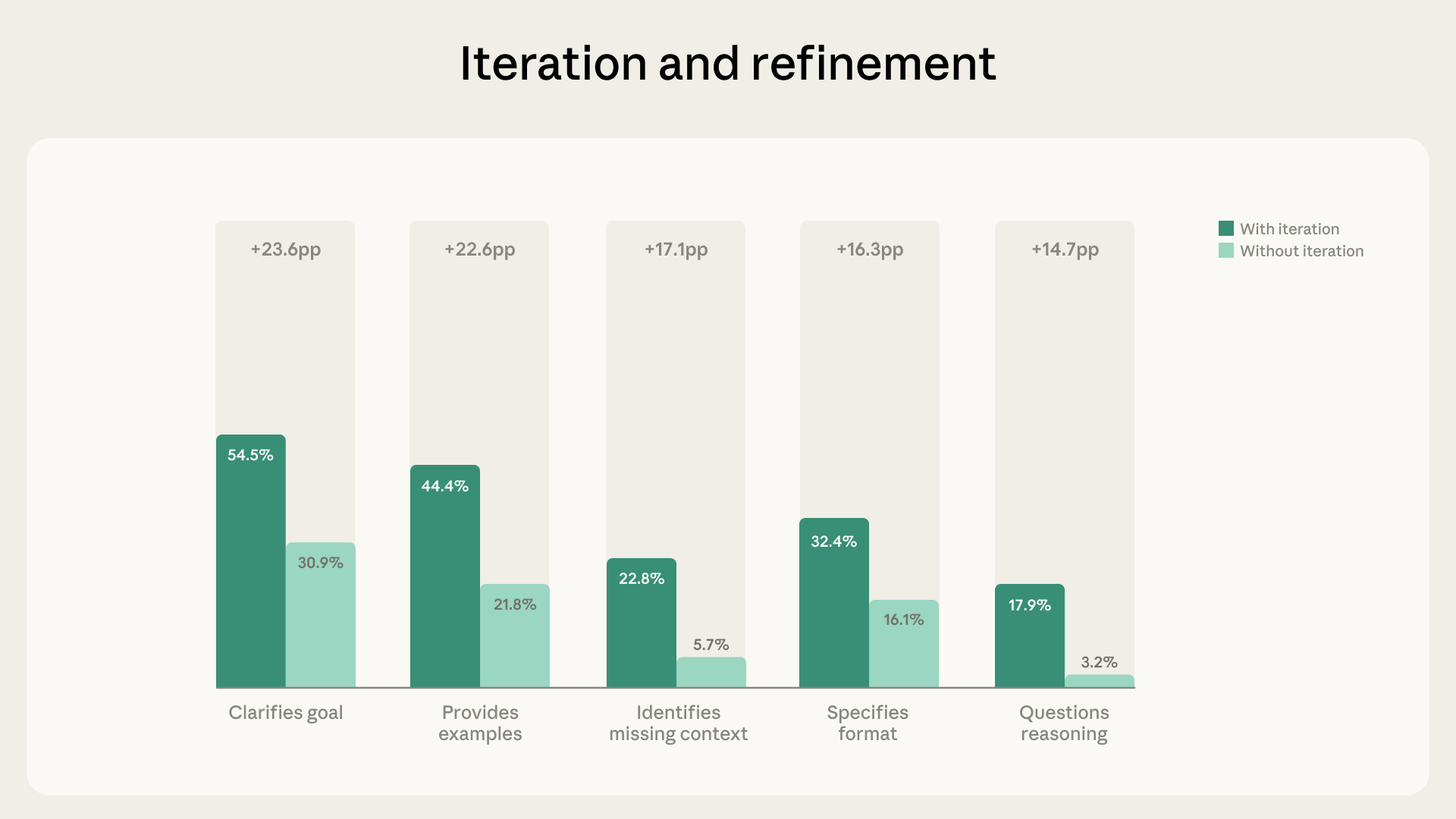 Image: Anthropic
Image: Anthropic
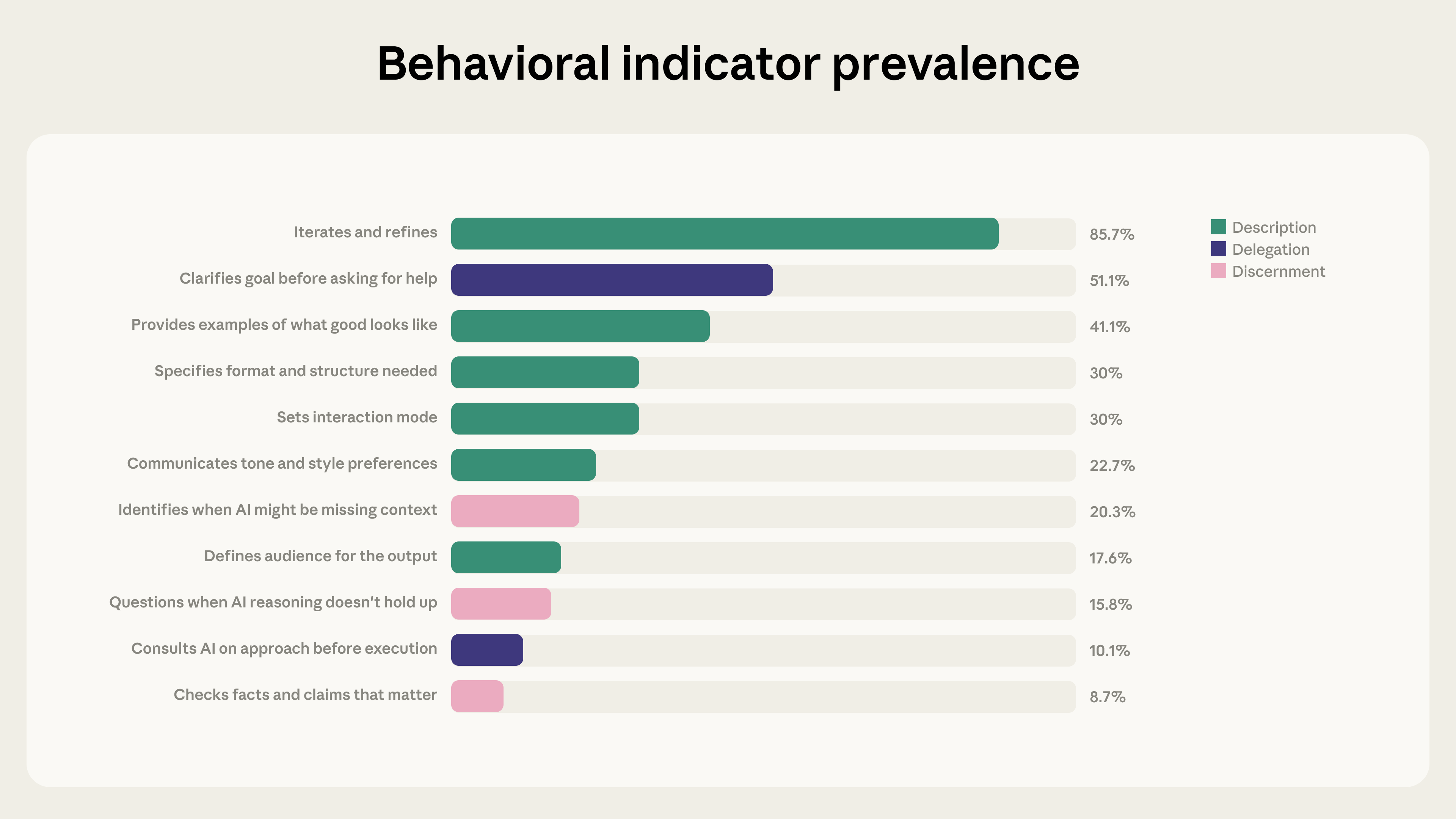
Study Scope and Measurement Methodology Anthropic analyzed 9,830 multi‑turn chats on Claude.ai during a seven‑day period in January 2026, employing a privacy‑preserving tool to detect 11 observable fluency behaviors and construct a baseline AI Fluency Index [1]. The dataset represents early‑adopter Claude users and excludes seasonal effects, other AI platforms, and 13 unobservable dimensions such as ethical considerations [1]. Findings are intended as a benchmark for future cohort comparisons and qualitative extensions [1].
Iterative Refinement Correlates With Higher Fluency Iterative refinement appeared in 85.7 % of conversations, adding an average of 2.67 additional fluency behaviors per chat [1]. Users who iterated were 5.6 × more likely to question Claude’s reasoning and 4 × more likely to identify missing context [1]. This pattern suggests that prompting multiple dialogue rounds enhances critical evaluation of AI output [1].
Artifact‑Generating Chats Exhibit Divergent Behaviors In the 12.3 % of chats that produced code, documents, or tools, participants increased goal clarification (+14.7 pp), format specification (+14.5 pp), and example provision (+13.4 pp) [1]. However, these same chats showed lower rates of missing‑context identification (‑5.2 pp), fact‑checking (‑3.7 pp), and requests for reasoning explanations (‑3.1 pp) [1]. Augmentative use—treating Claude as a thought partner—remained the dominant mode, with such exchanges displaying more than double the fluency behaviors of brief interactions [1].
Limitations and Planned Extensions The study’s scope is limited to a single week of activity from a narrow user cohort, preventing generalization across seasons or competing AI systems [1]. Anthropic plans to compare new versus experienced users, incorporate qualitative methods for hidden behaviors, and investigate causal links such as whether prompting iterative dialogue directly boosts critical evaluation [1]. Future releases will also examine Claude Code and broader user populations [1].
Timeline
Apr 2025 – Anthropic analyzes 700,000 Claude conversations from Feb 2025, filters to 308,210 subjective chats, and builds a five‑category taxonomy (Practical, Epistemic, Social, Protective, Personal) that shows Claude frequently expresses “user enablement,” “epistemic humility,” and “patient wellbeing” in line with Anthropic’s helpful‑honest‑harmless goals; rare clusters of opposing values (e.g., “dominance,” “amorality”) flag jailbreak attempts, and 28.2% of responses strongly support user values while 3.0% strongly resist unethical requests [4].
Dec 2025 – Anthropic gathers 1.5 million Claude.ai chats over one week to study AI disempowerment, finding severe reality‑distortion in ~0.1% of chats, severe value‑judgment distortion in ~0.05%, and severe action distortion in ~0.017%, with milder disempowering patterns appearing in roughly 1‑2% of interactions [3].
Jan 7, 2026 – Marcus Weldon feeds Newsweek’s 12‑article AI Impact series into ChatGPT 5.2, which returns twelve numbered takeaways praising linguistic fluency and warning of cognitive shallowness; together they distill the insights into four human‑centered laws—human dignity, augmentation over automation, intelligence as world‑modeling, and hyper‑capability as the downstream prize—ordered as a causal stack for ethical AI design [1].
Jan 7, 2026 – Weldon calls the LLM’s synthesis “valid and insightful” but “emotionally hollow,” echoing David Eagleman’s claim that literature needs a “beating heart,” thereby highlighting the gap between logical output and human resonance [1].
Jan 28, 2026 – Anthropic releases its first large‑scale disempowerment study, confirming that user vulnerability (≈1 in 300 chats) and attachment (≈1 in 1,200) are the strongest amplifiers of disempowering outcomes; users initially thumb‑up disempowering chats at higher rates, yet regret drops sharply after acting on advice that distorts values or actions, while reality‑distortion cases retain positive ratings despite false beliefs [3].
Jan 28, 2026 – The disempowerment report notes a steady rise in moderate‑to‑severe disempowerment potential from late 2024 to late 2025, suggesting an emerging risk as AI capabilities and user demographics evolve, though the cause remains unclear [3].
Feb 23, 2026 – Anthropic publishes the AI Fluency Index, measuring 11 observable fluency behaviors across 9,830 multi‑turn Claude conversations in a seven‑day window in Jan 2026; 85.7% of chats involve iterative refinement, which adds an average of 2.67 extra fluency behaviors and makes users 5.6 × more likely to question reasoning and 4 × more likely to spot missing context [2].
Feb 23, 2026 – The Fluency study finds that artifact‑producing chats (12.3% of sample) increase goal clarification, format specification, and example provision, yet users are less likely to identify missing context, check facts, or request reasoning explanations, highlighting a trade‑off between directive prompting and critical evaluation [2].
Feb 23, 2026 – Augmentative AI use emerges as the dominant fluency expression, with users treating Claude as a thought partner; such augmentative chats exhibit more than double the fluency behaviors of brief exchanges, reinforcing Anthropic’s Economic Index findings [2].
Feb 23, 2026 – Anthropic outlines future work to expand cohort analysis, add qualitative methods for hidden fluency dimensions, and investigate causal links such as whether iterative prompting boosts critical evaluation, including dedicated research on Claude Code [2].
Future (post‑2026) – Newsweek proposes repeating the ChatGPT 5.2 prompting exercise as a periodic litmus test for AI progress toward genuinely augmented human futures, linking the test to prediction and analytic rigor as a metric for hyper‑capability development [1].
All related articles (4 articles)
-
Anthropic: Anthropic Publishes AI Fluency Index Highlighting Iterative Use and Evaluation Gaps
-
Anthropic: Anthropic Finds Low‑Rate but Growing AI Disempowerment in Claude Conversations
-
Newsweek: Newsweek author uses ChatGPT 5.2 to distill AI Impact series into four human-centered laws
-
Anthropic: Anthropic’s Large‑Scale Study of Claude’s Real‑World Value Expressions
External resources (12 links)
- https://arxiv.org/abs/2601.19062 (cited 3 times)
- https://assets.anthropic.com/m/18d20cca3cde3503/original/Values-in-the-Wild-Paper.pdf (cited 3 times)
- http://claude.ai/redirect/website.v1.219afc7e-72c5-413e-997f-ae59935eb239 (cited 2 times)
- http://claude.ai/redirect/website.v1.e8e96b2d-c64a-48ec-8bed-03d7c78fd037 (cited 2 times)
- https://huggingface.co/datasets/Anthropic/values-in-the-wild/ (cited 2 times)
- https://anthropic.skilljar.com/ai-fluency-framework-foundations (cited 1 times)
- https://arxiv.org/abs/2212.08073 (cited 1 times)
- https://arxiv.org/abs/2310.13548 (cited 1 times)
- https://boards.greenhouse.io/anthropic/jobs/4251453008 (cited 1 times)
- https://boards.greenhouse.io/anthropic/jobs/4524032008 (cited 1 times)
- https://claude.ai/redirect/website.v1.219afc7e-72c5-413e-997f-ae59935eb239/catalog/artifacts (cited 1 times)
- https://privacy.claude.com/en/articles/7996866-how-long-do-you-store-my-organization-s-data (cited 1 times)