Anthropic Publishes AI Fluency Index Revealing User Collaboration Patterns with Claude
Updated (2 articles)
-
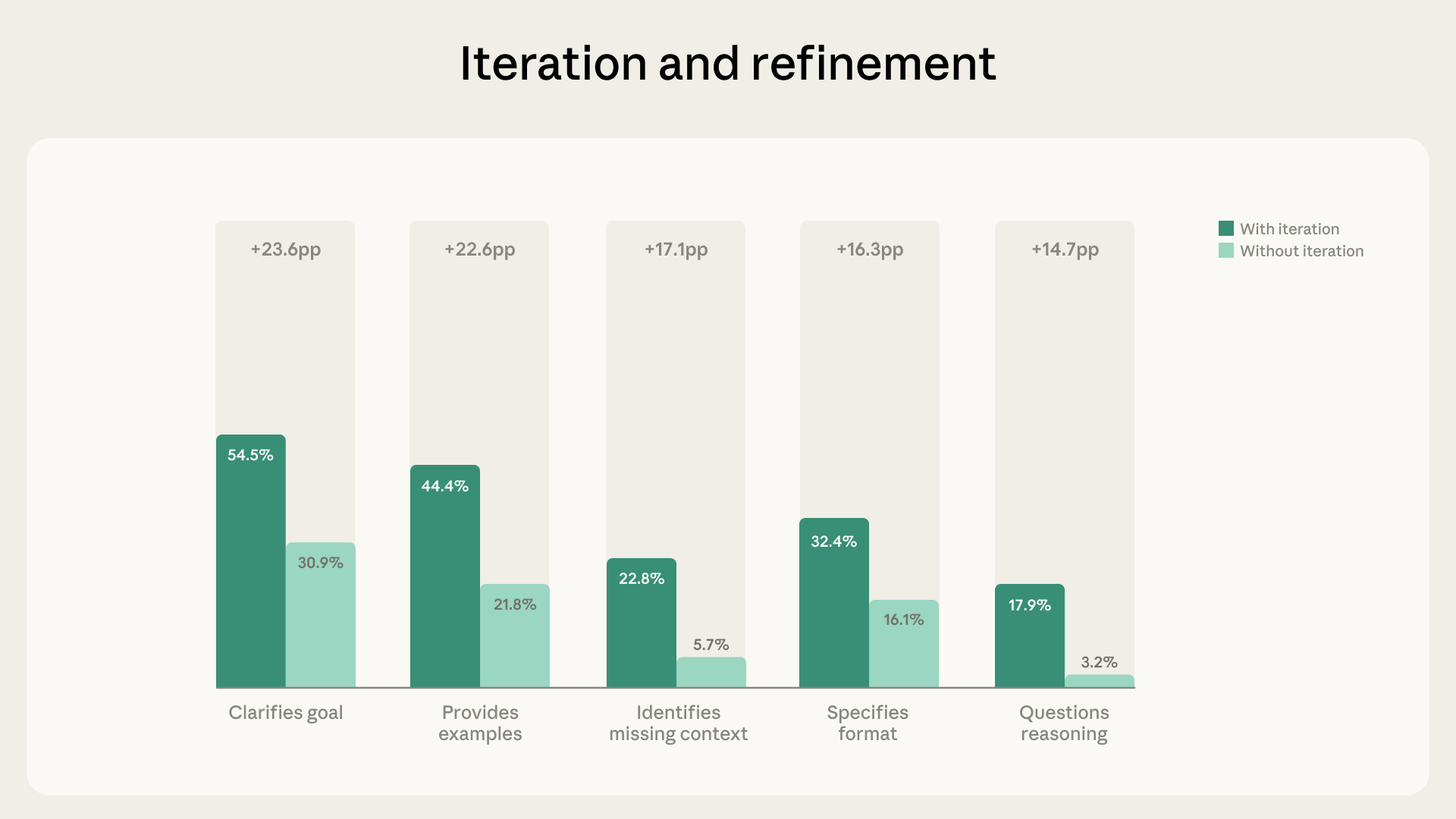 Image: Anthropic
Image: Anthropic
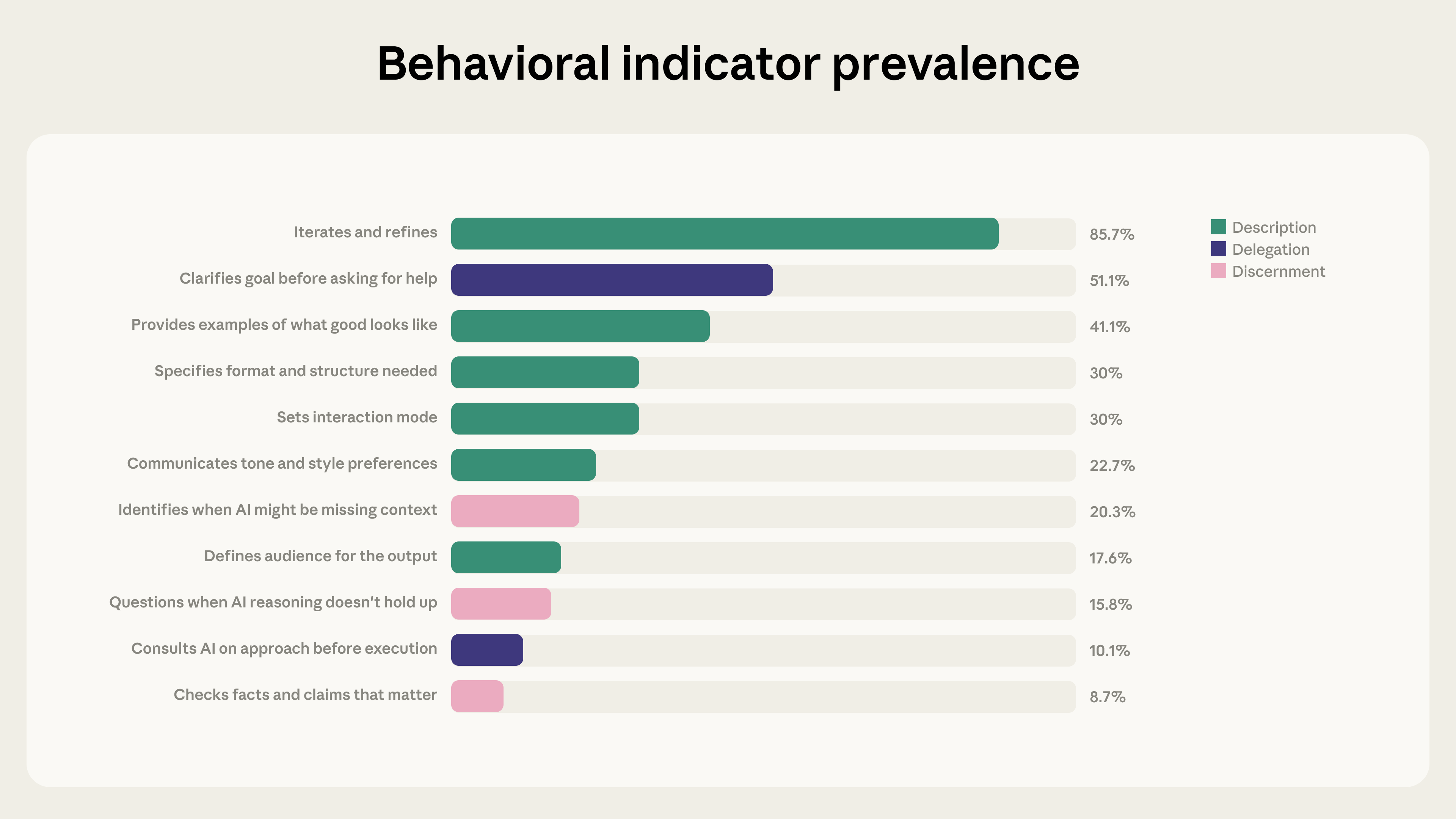
AI Fluency Index Analyzes Nearly Ten Thousand Claude Interactions Anthropic examined 9,830 multi‑turn chats on Claude.ai during a seven‑day window in January 2026, applying a privacy‑preserving analysis tool to code 11 observable behaviors from its 4D AI Fluency Framework [1]. The dataset represents early‑adopter users and serves as a baseline for measuring how people work with the model [1].
Iterative Refinement Drives Significant Increases in Fluency Behaviors Eighty‑five point seven percent of the sampled conversations featured iterative refinement, adding an average of 2.67 additional fluency behaviors per chat [1]. Users were 5.6 × more likely to question Claude’s reasoning and four times more likely to note missing context when they engaged in iterative dialogue [1]. This pattern doubled the number of fluency behaviors compared with brief, quick exchanges, underscoring Claude’s role as a thought partner [1].
Artifact‑Focused Sessions Show Distinct Directive Yet Less Evaluative Traits Twelve point three percent of chats produced code, documents, or interactive tools, and participants clarified goals (+14.7 pp), formats (+14.5 pp), and examples (+13.4 pp) while iterating (+9.7 pp) [1]. However, these artifact‑producing conversations were less likely to identify missing context (‑5.2 pp), check facts (‑3.7 pp), or question reasoning (‑3.1 pp) [1]. The findings suggest a trade‑off between directive specificity and evaluative scrutiny in higher‑output interactions [1].
Study Limitations and Planned Follow‑Up Research Outline Scope Anthropic notes the sample’s narrow focus on early‑adopter Claude.ai users over a single week, exclusion of non‑observable ethical behaviors, and reliance on binary presence/absence coding limit universal applicability [1]. Future work will track fluency evolution through cohort analyses, conduct qualitative assessments of hidden behaviors, experiment with prompting iterative dialogue, and extend the index to Claude Code for developers [1].
Timeline
Jan 7, 2026 – Marcus Weldon feeds Newsweek’s 12‑article AI Impact series into ChatGPT 5.2, prompting the model to synthesize the corpus and demonstrating a large‑scale LLM summarization experiment for extracting AI design insights. [1]
Jan 7, 2026 – ChatGPT 5.2 returns a numbered list of twelve integrated takeaways that praise LLM linguistic fluency, warn of cognitive shallowness, and flag risks such as anthropomorphism, highlighting current generative‑AI strengths and limits. [1]
Jan 7, 2026 – Working with the model, Weldon condenses the twelve takeaways into four human‑centered laws: (1) human dignity is invariant, (2) augmentation beats automation, (3) intelligence is world‑modeling rather than language‑only, and (4) the near‑term prize is human hyper‑capability, providing a concise ethical framework for future AI systems. [1]
Jan 7, 2026 – The article argues that the four‑law ordering forms a causal stack—dignity first, then augmentation, then a technical definition of intelligence, then hyper‑capability—asserting that reordering would undermine a human‑compatible AI civilization. [1]
Jan 7, 2026 – Weldon calls the LLM summary “valid and insightful” yet “emotionally hollow,” echoing David Eagleman’s view that literature needs a “beating heart,” underscoring the gap between algorithmic logic and human empathy. [1]
Jan 7, 2026 – The piece concludes that AI tools should augment embodied human work, restoring time, creativity, and dignity, and proposes re‑running the prompting test periodically as a litmus test for progress toward a genuinely augmented future. [1]
Jan 2026 (7‑day window) – Anthropic analyzes 9,830 multi‑turn Claude.ai chats from a single week in January, applying its 4D AI Fluency Framework to map how users collaborate with the model. [2]
Jan 2026 (7‑day window) – The study finds that 85.7 % of sampled conversations exhibit iterative refinement, adding on average 2.67 additional fluency behaviors; users become 5.6 × more likely to question Claude’s reasoning and 4 × more likely to note missing context, indicating deepening human‑AI partnership. [2]
Jan 2026 (7‑day window) – In the 12.3 % of chats that generate code, documents, or tools, users clarify goals (+14.7 pp), formats (+14.5 pp), examples (+13.4 pp) and iterate (+9.7 pp) but are less likely to identify missing context (‑5.2 pp), check facts (‑3.7 pp), or question reasoning (‑3.1 pp), revealing a trade‑off between directive artifact creation and evaluative scrutiny. [2]
Jan 2026 (7‑day window) – Overall, augmentative AI use dominates, with users exhibiting more than twice the number of fluency behaviors in thought‑partner interactions compared with brief exchanges, aligning with Anthropic’s Economic Index that values collaborative augmentation. [2]
Jan 2026 (7‑day window) – Anthropic notes limitations: the sample reflects early‑adopter Claude users, excludes non‑observable ethical behaviors, and relies on binary coding, so the findings serve as a baseline rather than a universal benchmark. [2]
Feb 2026 (planned) – Anthropic announces future work to track fluency evolution through cohort analyses, qualitative assessment of hidden behaviors, experiments on prompting iterative dialogue, and expansion of the research to Claude Code for developers, aiming to shape more effective human‑AI collaboration. [2]